這是通常用於某種資料,在觀察資料的時候,無法固定其中某些不確定因素,
為了消除混雜因素的影響使其他因素不變,而採用的測試方法。
通常採用此test的狀況為:
- 兩種同質對象分別接受兩種不同的處理,如性別、年齡、體重、病情程度相同配成對。
- 同一受試對象或同一樣本的兩個部分,分別接受兩種不同的處理
- 自身對比。即同一受試對象處理前後的結果進行比較。
附註:
在樣本數大(超過30)的時候通常採用Z test,
然而Z test在小樣本的時候會產生很大的誤差
因此採用t test
ex:
比如觀察某班高中生補數學是否對成績有所幫助
若取樣每個人的成績,無法使每個人的智慧或其他個因素都相同
因此通常是採用同一個人在補習前、補習後的成績比較,
然後觀察補習後平均是否可以比補習前的成績還要來得高或者無影響,甚或是降低成績
接著為了知道:"補習與成績升降是否有關係"
往往會做一個假設H0(null hypothesis),
假設補習後的成績樣本(平均X)與補習前的(平均μ)相同
i.e. H0: X = μ
與
H1(alternative hypothesis):
X ≠μ (two tail)
然後根據significance level α(檢驗水準) 與d.f.(自由度, d.f = 樣本數-1 ) 查表得到值
(如果不是在t分布, 而是在Z分布中, α =0.05即是95信賴區間的兩側)
接著透過下列公式算出:
如果在區間內,我們就do not reject H0。
[因為Pr(| ) = 95% ]
否則當或我們就reject H0
若現在求出的tstat < tα/2表示我們不能否認H0的假設,即補習前後成績平均可能相同
[如何得到p值 How to get p-value] example2 (from ref3)
難產兒體重 n=35, 平均X=3.42 S = 0.40
一般嬰兒平均體重為μ=3.30
null hypothesis - H0: 總均數相等
alternative hypothesis - H1: 總均數不等
t = (3.42-3.30) / [ 0.4/ sqrt(35) ] =1.77
自由度v (or df.) = 35-1 = 34
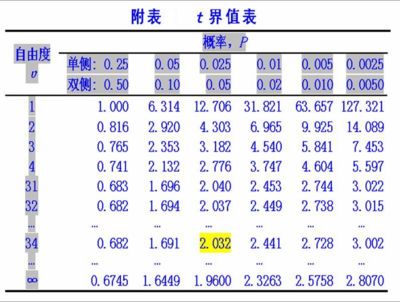
如圖可知t落在第2欄與第3欄之間, 因此 0.10 > p > 0.05 (two-tail雙側, p看第二排)
若按α = 0.05的水準, t=1.77 < 2.032 (tstat < tα/2)
因此不能否認H0,也就是兩者平均可能相等
以p-value來看,p-value 大於 α,因此兩者無明顯差異,可能均數相同
----
資料來源:
ref1: ※wiki的Student's t-distribution.
http://zh.wikipedia.org/wiki/%E5%AD%A6%E7%94%9Ft-%E5%88%86%E5%B8%83
ref2: ※下面這個文章介紹了t-test的方法:
http://hanzi.boskijr.com/2012/12/t-test/
ref3: ※下面這個文章有unpaired t-test之範例, 與paired t-test之說明
(單個樣本的t檢驗實例分析, 與 配對樣本t檢驗 兩部分)
http://wiki.mbalib.com/zh-tw/T%E6%A3%80%E9%AA%8C